 I’ve heard many stories about people in East Asia who try to learn English by memorising dictionaries. Even if it’s true that some people actually do that, I think this somewhat puzzling technique isn’t common in the West.
I’ve heard many stories about people in East Asia who try to learn English by memorising dictionaries. Even if it’s true that some people actually do that, I think this somewhat puzzling technique isn’t common in the West.
Hearing such stories, it’s easy to shake one’s head and wonder how someone could be so stupid as to think that memorising dictionaries is the same as learning a language.
Memorising dictionaries to boost Chinese reading ability
Then it may come as a surprise that a couple of years ago I spent roughly one hundred hours spread out over six weeks learning all the characters in the Far East 3000 Chinese Characters Dictionary.
Of course, I knew most of them already, but I learnt a considerable amount of new words as well. This article is not about this particular thing or about this dictionary. Any dictionary (or website) based on frequently use characters and/or words will be fine. Here are some suggestions:
The most common Chinese words, characters and components for language learners and teachers
I’ll try to explain why I think that going through such lists is an excellent idea if you do it right and at the right time, and I will also share some thoughts on how to do this without running into some of the problems I did. I never expected this, but the day has come when I actually recommend other people to memorise a dictionary!
Please note that you should only do something like this if you already know the majority of words in the list you want to study. It’s up to you, but I would rather aim slightly too low than too high.
Learning a dictionary isn’t necessarily stupid
First things first, why would memorising a dictionary be a good idea? I’ve argued before that Chinese is a language consisting of many building blocks (see my articles about building a toolkit) and rather than learning a character as a whole, it’s fruitful to learn its composition as well.
The same goes for words in Chinese (words consisting of more than one character). Making sure that you know the 3000 most common characters, you gain access to a huge number of new words.
By access I mean:
- You can guess the meaning of a compound word because you know the characters in it
- You can learn new words more easily, because you know the component characters already
I have argued elsewhere that vocabulary is not only king, but god emperor as well. If you don’t feel convinced that vocabulary is extremely important, you should check my article about the importance of knowing many words.
Let’s look closer at the above-mentioned benefits. The first one might be either useless or invaluable depending on the word. Chinese consists of lots synonym compounds (i.e. words that consist of two characters which mean the same thing, such as 快捷 or 馈赠 (饋贈)) and if you know both the characters, you can be pretty sure about what the word means, whereas if you only know one, the meaning could be anything. This is an example of where your toolkit allows you to learn words for free, so to speak.
Moreover, there are numerous examples where there are more than one similar way of saying something. For instance, compare 时限 (時限), 期限 and 年限, which are easy to distinguish if you know what the individual characters mean, but might cause trouble if you only look at the English translations. There are of course more examples, but I think this is enough to illustrate the point.
Now, let’s look at a graph I think some of you have seen before:
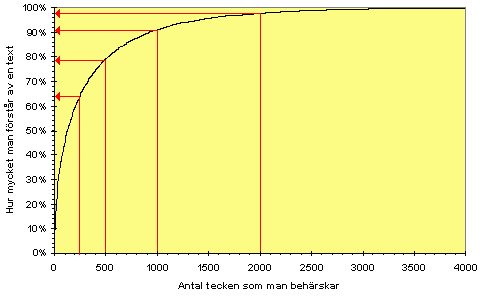
The picture is from Patrick Zein’s excellent introduction to Chinese (in Swedish, sorry). On the X-axis is number of characters one knows and on the Y-axis is the expected ability to understand written Chinese, assuming that grammar and character combinations are not a problem (which they of course are, but that’s not the issue here).
What does this graph tell us? Basically, it shows that if we know 3000 characters, we will very rarely come upon characters we don’t know when we read normal Chinese text, provided that we know the correct 3000 characters. If you’ve spent lots of time learning characters that aren’t within the 3000 most common, referring to this graph is meaningless. Naturally, knowing characters does not equate to being able to read either, but it is a prerequisite.
Using frequency lists to plug holes and make your foundation more solid
Going through lists of words based on frequency allows you to learn characters you should know (because they are common), but have missed because you haven’t come across them yet, maybe because they aren’t in your course, or it might be just a fluke you haven’t stumbled upon them yet.
This means that you broaden your base, including more words that lie outside your textbook and your course, but within your general range. This provides you with a more solid foundation which you can later use to learn more words and understand spoken and written Chinese with more ease.
Suggestions and tips
After having said all this, I’d still like to say that memorising dictionaries is quite stupid.
Of course, you shouldn’t just try to commit everything to memory by rote learning, you should use all the clever hacks I talk about in other articles. You use a frequency list to find commonly used words and to gain information about these words.
However, this is not enough. Here is some more advice for you:
- Be careful, sometimes you just think you know what a character means because it’s so common, but in fact it means something completely different when it’s on its own. Check all characters carefully once. This will either allow you to find flaws in your knowledge, or, if no such flaws are found, it will increase your confidence.
- Learn at least one example word and/or phrase where a given character appears, also make a note of this word in connection with the single character so that when you review it, you always see it in context. Learning words in complete isolation is bad for a number of reasons.
- Don’t feel forced to use the example words in the book. Some dictionaries provide examples that are quite rare. Dictionaries tend to focus on accuracy which isn’t necessarily a good idea. Use HanziCraft (frequency sorting at the bottom). Pleco can also show you words a character is contained in, sorted by frequency.
- If your list is sorted alphabetically, don’t learn the words in alphabetical order, because it will be extremely hard to distinguish between one hundred different “shi” you learnt at the same time. A better way would be to learn the first character on every page, then the next time learn the second character on every page.
- Spread it out! Even if you’ve studied for a while, 3000 characters will take a while to go through (100 hours in my case). I managed this by portioning it out, going through a dozen characters at a time whenever I had some time to spare.
Some final words
Conclusively, memorising dictionaries is not a very good idea in general, but I think there is some merit in studying frequency lists, thus making sure you know characters and/or words you really should know.
When I did this, I felt that the 3000 characters resulted in a quantum leap in reading comprehension. This will not take care of reading speed, complex grammar or other problems associated with reading ability, but it will enable you to understand many texts you would otherwise have been completely unable to decipher.
More importantly, it will make it a lot easier for you to learn more later, given that you now have more building blocks and tools to understand and analyse the language you are learning!

Tips and tricks for how to learn Chinese directly in your inbox
I've been learning and teaching Chinese for more than a decade. My goal is to help you find a way of learning that works for you. Sign up to my newsletter for a 7-day crash course in how to learn, as well as weekly ideas for how to improve your learning!
39 comments
Actually your post makes absolute sense. When you’re a beginner it is useful to use something like Tuttle’s Learning Chinese characters, which has the first 800 in frequency order with easy memory tricks. I used to cross reference their number to my text book, and then at the end of the first year I just went and learnt the rest that hadn’t been covered.
I’m now paging through Chinese Character Fast finder (also Tuttle / Matthews) which is shape / radical based, with 3200 character, and more useful like you mention than something that is alphabetical – and yes I do kind of sit down and learn a page from time to time.
Linked (https://docs.google.com/spreadsheet/pub?hl=en_US&hl=en_US&key=0AqJaLYri_ZnYdF9YWG0zR3F5UDN6Nll5Q2d5MUM4UWc&single=true&gid=1&output=html) is a visualisation of character frequency, making the same point as the chart on this page.
(I can’t work out how to make the chart bigger on google docs, and for some reason it doesn’t like Explorer, but you can drill down a bit, and also hover your mouse if you want to see which character is which.)
@Paul: Thanks for sharing! What I like most is that this gives me a feeling for what character frequency means. Just viewing the words in a list is one thing and you can see where a certain character is, but this is a lot clearer. Is the size of each cell representative of the characters frequency? If so, where did you get the frequency data?
Yes, the size of the cell is proportional to the usage – frequency data is from the Modern Chinese Character Frequency List compiled here: http://lingua.mtsu.edu/chinese-computing/statistics/
What I would really like to do is to match this up with radicals as well – if anyone knows where to find a text version of characters sorted by radical (i.e. the front index section of a dictionary), I can do this. That way, it can tell you not only which characters you might focus on, but the radicals that are most important to know as well.
@Paul: This is really cool and it would be even more awesome for radicals. However, is the front page of a dictionary enough? Don’t you want all the characters in the dictionary listed by radical? There should of course be such lists, but I haven’t found anything yet. I’m going to Berlin later tonight and won’t be able to look more until next week when I get back. How about asking for this on http://www.chinese-forums.com? Someone should be able to help you!
By the front page, what I actually mean is what my paper dictionary calls the 检字表 – the second stage of the character lookup when all the characters are listed by radical then stroke order before it tells you which page to look on. I’ll see how I go hunting..
Yeah, I know what you mean. I’ll do my best to help, but I probably won’t have time until next week. Let me know if you find anything!
Olle – how did you go about entering / uploading the dictionary to Anki?
The reason I ask is that I would like to do something very similar for a different language. There are no online versions of the dictionary so I can only think of entering the vocabulary manually, which is clearly going to be time consuming.
Your advice would be massively appreciated!
Hi Trystan,
The boring but true answer is that I just typed in all the characters, definitions and example sentences. Did it take a lot of time? Yes, of course. Do I think that time was wasted? No, definitely not. Retying example sentences and making sure they are correct is a way of studying, selecting the right character from a list to match the character in a book is a way of reviewing. And so on. I don’t think creating one’s own word lists by manually inputting words is a bad idea.
I downloaded the SUBTLEX chinese frequency list of words found in subtitles of TV shows, matched it up with HSK lists and have been going downwards through those.
Even in the first 300 i found some gaps which have really helped me… read subtitles! For example 家伙 is like “guy” and used a lot casually and in action movies, but is considered HSK6. But in subtitles it’s as common as 穿 or 写.
What I do is go through them, and mark how well i know the word on a scale of 1-5. 1 is a blank. 2 is seen before but pretty unfamiliar. 3 is I know the word but not well. 4 is in my SRS but not perfect yet. 5 is I can write this character from memory reliably.
Words that are 1-3 go into my SRS via an example sentence. I also have a report of all the words rated 1-4 and occasionally check through them to see if they can be promoted. SRS does this too, so it’s almost repetition, but SRS doesn’t know which ones are highest frequency words.
And for fun, I also calculate the total % so I have a rough idea of the % of words I understand. Right now it’s 70% at 5 although actually there’s quite a few words I haven’t rated yet so perhaps more like 75%-80% are 3-5 when I mark further down.
Sounds interesting! Can you offer some more information about that list? Also, I’m a bit surprised that 傢伙 is HSK6, it’s really quite common!
You can download the data here: http://expsy.ugent.be/subtlex-ch/
There is a paper (easy to find online) that explains the data better, after reading the abstract I was happy enough about their segmentation strategy – I’m no linguistics expert, but I was convinced enough to use it.
So I just load up a big old Excel file and I search away. I’ve sorted it all on frequency and just work my way down the list.
It’s also fun to look for the most common 3 character and 4 character words (不好意思 is the most common).
How did you match the list up with the HSK lists in excel? I mean, how can you compare what is in both automatically?
Hi, Olle – when you were learning those 3000 characters, how did you handle multiple meanings of a character? For example, the CEDICT dictionary may give 5, 10 or even more meanings for a single character. Did you try to remember them all, or only a few most important of them? In the latter case, how many of them, approximately, did you retain for your studies? How did you decide which ones are the most important?
Thank you in advance for the answer!
There’s usually a core meaning and I would say it’s very rare with characters that have five or ten different meanings. I would focus on this meaning. The goal isn’t to learn all possible meanings of a character, that would take ten times as long and would be quite pointless.
Olle, thank you for the reply. I fully agree that memorizing all meanings of a character is pointless. That’s why I asked this question in the first place – how to determine which 2-3 meanings are most important, or better yet, which meaning is the core meaning, as you call it.
You say, it’s rare to see a character with five or ten different meanings. I guess it’s only because you are now way beyond the first 3000 characters and so this is what you usually see for not very frequent characters. However, for more frequent characters it’s not so rare to see many meanings. Just a few examples:
薄:
bo2 – meager; slight; weak; ungenerous or unkind; frivolous; to despise; to belittle; to look down on; to approach
bo4 – peppermint
bao2 – thin; cold in manner; indifferent; weak; light; infertile
涂 tu2 – to apply (paint); to smear; to daub; to blot out; to scribble; to scrawl; mud; street; way, route, road
灵 ling2 – quick; alert; efficacious; effective; to come true; spirit; departed soul; coffin
承 cheng2 – to bear; to carry; to hold; to continue; to undertake; to take charge; owing to; due to; to receive
Of the character 灵 I know the meaning “spirit”, which is the sixth one. Which is the core one for this character?
It is similar for me with the character 承, I only know one of its meanings – “to undertake,” the fifth in the list. But which one is the core one?
It’s a pity that nobody has answered my question yet, it’s really important for me.
In the meantime, I’d like to extend my question by giving one more example. (This character is in my current list right now.)
The character: 逼 [bī]. Dictionaries give me the following meanings:
1. to force, to compel;
2. to drive;
3. to press for, to extort;
4. to close in on.
Which meaning (or meanings) should I choose for memorizing?
Generally, not only do I need an answer to this particular question, but I also would like to understand the general approach, how to select the main meaning(s) of the character. (Please see also my previous comment here.)
Thanks for posting another comment; I might have missed your first one if you didn’t. I run this site on my spare time and I receive tons of e-mails and comments, and it’s becoming harder and harder to respond to everyone.
In general, I think you can see that most of the characters you mentioned actually don’t have that many meanings or that they are related in groups.
For instance, regarding 涂, I see two meanings there, one which is related to writing/smearing/applying stuff to something, and one which is related to road. This character doesn’t have 11 different meanings, it’s just that it’s hard to capture the basic meaning in one English word.
In general, though, you need a good dictionary, which will either list the most common one first or the original meaning first. I just checked Pleco’s CE dictionary for 逼 and it lists each meaning with examples and translation. I need to verify this, but it looks like the most common one comes first.
If this doesn’t work, you can take a short cut and see which meaning the character has in the common words you know. For instance, if you learn 逼迫, any good dictionary will tell you that in this word, 逼 means “force, compel”. Learn that and care about the other meanings when you learn words that contain them.
Hope this helps! There is no quick fix to your problem, but basing it on what you’re actually learning and not focusing too much on learning from dictionaries is probably a good idea. Remember that I combined this approach with a full immersion environment and knew about 2/3 of the characters when starting. I do NOT recommend this as your main approach.
This is the exact book which I used to learn Chinese characters while I was in Taiwan. The method I used was to write every character on the front of a flash card with the pronunciation (I chose to use Zhu Yin instead of Pinyin) and meaning on the back. This took hours, not sure how many, but was well worth it.
I did do this in alphabetical order which helped me learn how to pronounce characters by looking at them, you’ll find quite a few patterns in there and learn how some parts affect the sound and meaning. By the end I knew how to write any character I saw, and was good at guessing pronunciation and meaning.
I did not memorize them in alphabetical order, but rather with the flashcards I mixed them up well, and remixed them every week or so as to prevent me from learning them in this stack, a problem I find with learning languages in Rosetta stone is that I know the language while I am in that lesson on the computer.
Since then I have struggled to find a good list to add to my 3000 base, other than just learning characters that I come across. I do have the little yellow dictionary with over 12,000 characters with the radical and stroke lookup, but as you get higher in the number of characters the usefulness and frequency drops way down.
I have used a frequency list to learn up to around 6000 characters. This is completely useless from a practical point of view and I did this as a challenge and to learn more about learning characters. I strongly believe that learning characters after 2500-3500 should be on a need-to basis only, unless you think it’s fun to learn characters. Most of the characters I learnt this semester have no impact at all on my Chinese proficiency and I might never see some of them ever again. As you say, there are so many infrequent characters used only in place names and so on.
The list of 3,000 characters in that dictionary is good for the corpus of publications it was drawn from. Character frequency can be very different in other situations. Some of those—such as restaurant menus—are very important for language learners. Before jumping into a huge list of characters, I think it’s worthwhile to consider one’s language goals and see how close they are to the goals of the curators of the list.
This is the exact book I used to learn my first 3000 characters. Please note, I had studied two common vocabulary books first before taking a crack at this book.
My method was to write every character on a business card size flash card with the character on the front, and Chinese Phonetics on the back (注音) with its corresponding definition. One thing you’ll find is that characters with multiple meanings may only have the other meanings when pronounced differently. To save on time I generally only included a single example word rather than copying the entire dictionary verbatim. The flash cards were easy to find in Taiwan in stacks of 100, which made a total of 30 boxes.
By copying every character by hand in phonetic order as the book is laid out I gained a huge understanding of the construction of Chinese characters and how you can often guess the phonetic from its composition. It also helped to understand stroke order and gain the ability to copy any character that I see.
My reasoning with using Chinese Phonetics was to force myself to learn them, which has helped with typing, reading, and writing, especially if the writing will be seen by a Taiwanese person, if I don’t know the character, I can write the phonetic and they’ll understand.
With the flash cards I could then shuffle decks together and separate them back to 30 decks and spend a week memorizing them before shuffling again to avoid falling into the habit of knowing certain characters by the deck they were in.
I have found it hard to go beyond the 3000 characters, and sadly I also no longer have my original 3000 flashcards. That is not to say that I have not expanded beyond them, just that it is hard to find material to extend past that, and hard to quantify the current number of characters I now know, and to know which ones I don’t or have simply forgot.
I think you should try out Skritter or, if you don’t want a subscription service, programs like Anki (free and very versatile) or Pleco (one-time purchase but more suitable for Chinese). I know several people who started out with paper flashcards, not because of ignorance of digital alternatives, but because they preferred it that way. However, none have stuck to them, so they’ve either stopped using them altogether or switched to digital. Personally, I think this is the only realistic way of maintaining a large vocabulary with little time. You should of course use the language too, but the natural repetition you get from reading takes much more time and even if it would be better, it simply doesn’t work if you only have 10 minutes per day.
Hey there, You’ve done a great job. I’ll certainly digg it and for my part
recommend to my friends. I am sure they’ll be benefited from
this web site.
There’s a Quora post which claims the character standard for Chinese middle school students is about 3500. By implication, you want to know about 3500 characters for proficiency comparable to a middle-schooler. There’s also quite a few claims that you need 5000 characters to read a newspaper comfortably, so I don’t see why going above 5000 is a bad thing.
I also don’t see the problem with East Asians trying to memorize English dictionaries, although frequency dictionaries are better for this purpose. The important distinction to be made is that this isn’t actual language learning, but preparation for language learning. Actual language proficiency refers to the ability to understand and produce materials in the target language and mastery of vocabulary is a prerequisite, but not identical to being proficient in the language. Vocabulary cramming allows you to address the tasks individually, so that listening, speaking, writing, and reading can be unencumbered by unfamiliar words.
Regarding the number of characters, that roughly matches my experience as a learner. Characters beyond the most common 5000 start being really specific, often names of mountains, rivers, emperors and so on. There are also non-names, of course, but then usually they are part of one single word or expression that’s usually limited to written language. I think the cut-off for practical use is 5000 or thereabouts, unless you want to read text that aren’t in modern Chinese.
I agree that memorising dictionaries is good preparation for language learning (that’s what this article is about), but if someone only does the prep work and not the actual language learning, it isn’t very good. I think it’s clear that when compared to Western language teaching, East Asian countries tend to favour memorisation over actual communicative ability. Memorising a dictionary is only useful if you combine it with other activities, like you say.
Part of the deal is active vs passive vocabulary; i.e, once you get past 5000 the amount of effort put on retaining characters beyond recognition can begin to drop as these just become low frequency, and as you say, more important for proper nouns. 文言文 I’m told also ends up a lot in modern Chinese, putting more obscure characters alongside traditional characters into the fore.
One nice thing about Chinese characters is that they’re tough to learn over the first 1000-2000 or so, but once you move on, the characters are merely variants of each other with differing meanings and pronunciation. And the rare character that beats this pattern becomes notable and memorizable for that reason.
As far as vocabulary cramming goes, the most notable trait of this is front-loading, i.e, the effort is intensive at the beginning but makes things easier toward the end. The pure dictionary memorization approach basically means you’re stuck processing up to ten thousand words before you can begin the praxis / 实践 level. If you have a lot of time and/or are efficient at memorizing words, this can work. If you’re doing an hour a day, you’ll be lucky to get even 25 Chinese words memorized per day, implying a prep period of more than a year before you can actually learn the language. Stuff like English, on the other hand, is memorized faster so to get to the 10k mark, you would “only” need 3-4 months at a pace of 100 English words a day.
And of course, the prep method would require preparation on its own in attacking pronunciation and the ability to use a dictionary. You’d need two levels of dictionary work as you move from bilingual dictionaries to intra-lingual dictionaries. Huge amounts of front-loading. But I’m looking forward to doing 10k words of French in 2 weeks under self-employment conditions.
Chinese isn’t that bad, though. For instance, the loanwords and Confucian culture mean that translations from Japanese and Korean have higher fidelity than to English. Likewise, Chinese is purportedly higher in text-based reading speed (content per hour) than any other language, so if you want to make Chinese a primary language it has its benefits.
Would be very interested in a citation for that!
“I think it’s clear that when compared to Western language teaching, East Asian countries tend to favour memorisation over actual communicative ability.”
I think in the case of language learning there is an advantage to classroom teachers focusing on areas they can make the most difference. For a Chinese English teacher with a class of 30 kids it’s really hard to build speaking and communication skills effectively, but it is much easier to teach reading, writing, vocab, grammar, and perhaps listening. These are useful skills and maybe it’s better to focus on them even to the exclusion of spoken communication. It’s a lot easier for them to build off those skills later on and develop full communicative competence, particularly if they have a large prelearned vocab to leverage off, but even if they don’t being able to read and write is still useful.
This is probably also why 外教 usually end of teaching ‘oral English’!
Other thing I’ll point out is this:
https://en.wikipedia.org/wiki/Table_of_General_Standard_Chinese_Characters
3500 frequents, 6500 common characters. Not the same as getting vocabulary up on its own, due to the frequency of compounds, but most languages need 10,000 words to be fluent and 20,000 words to have near-native mastery levels.
Yes, although the numbers you gave are somewhat arbitrary. Near-native level probably includes much much more than 20,000 words in Chinese. I had 25,000 facts in Anki while I was at some kind of upper-intermediate level and that wasn’t even close to near-native level. Naturally and as usual, it depends on what’s counted as a word, hence the use of “arbitrary” above. I think the 20,000 you mentioned usually refers to root words, not inflections and variations of the same word. However, that’s quite tricky to judge and compare between languages!
The numbers I’ve seen for Chinese range to 22,000 words for a beginning undergrad. Japanese supposedly sees 45,000 words for an educated adult native speaker, and English is around 35,000 words.
Part of the fun of Chinese is realizing that there’s a time to stop, ironically. Since the estimated time for an English speaker is supposed to be around 4,000 hours to reach C1 proficiency, the average learner is likely to end up setting targets for use, i.e, business Chinese, restaurant Chinese, dating Chinese, etc. HSK 4 targets should be doable in only 1,000 hours and make someone passable at 口语 and low-level conversations.
The dismissal of dictionaries in the polyglot community has always seemed strange to me.
I love the idea of progressively going one word per page.
I have enjoyed alphabetical work, however. For people who employ Memory Palaces, it can work very well.
But with what you’re suggesting, mnemonists could use each page as a Memory Palace and perhaps encode 3 words per page.
Hi Olle,
Do I understand right that you first learned most of the words (as compounds of two characters) and then later went back to learn the individual characters as well?
Do you think you benefited from this approach or would you have rather learned the individual characters along with the word when you first learned it?
I keep finding myself wanting to understand the individual characters of new words that I learn because it gives me a more “grounded” understanding but I’m not sure if that’s actually a viable approach because it does slow down acquisition of new vocabulary down quite a bit, at least in the short-term.
I have never used an extremely structured approach, considering that I’ve studied and learnt Chinese under so many different conditions, but I would say that I normally learnt most individual characters when learning words, but as this experiment showed, there were a fair number of individual characters I did not know, or just kind of knew. Nowadays, I would recommend students to always start from the basic unit of communication (words) and then learn individual characters and components whenever it helps to do so. Not compulsively learn every single individual character and every component of every character, but at least look them up and see what makes sense and use that.